Datos de Calidad y el Corona Virus
Ricardo Baeza-Yates, @polarbearby ……… A shorter version in English
Se dice frecuentemente e incorrectamente que los datos son el petróleo del siglo XXI, pero una diferencia fundamental es que la producción de datos es creciente en el tiempo e ilimitada, exactamente lo contrario del oro negro. Por esto hablamos de datos masivos o big data que serán aún más grandes en el futuro. Otra diferencia crucial es que el petróleo, independientemente de su procedencia, siempre tiene una calidad mínima y cumple con su cometido final. Por otro lado, hay datos que son excelentes, pero hay muchos más que son imprecisos, inválidos, incorrectos, incompletos e incluso inútiles, sobre todo cuando la complejidad del proceso que genera los datos es mayor. Y cuando los datos son basura, pueden ser muy peligrosos. Y que mejor ejemplo hoy que los datos provenientes de la pandemia del COVID-19, un novel corona virus. Analicemos entonces más a fondo cuán importante es la calidad de los datos.
“Cuando los datos son basura pueden ser muy peligrosos.”
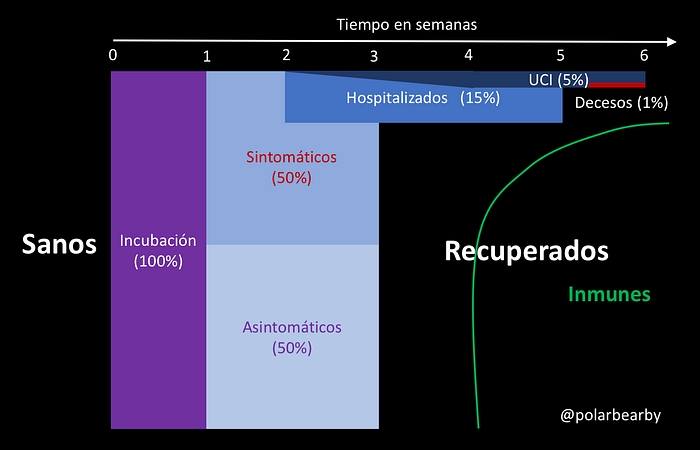
La evolución de una pandemia es en si misma un problema complejo, más aún en el caso del novel corona virus, por las distintas fases que puede tener a partir del contagio: 1 a 14 días de incubación (5 días en promedio, digamos una semana) y luego de 2 a 6 semanas de enfermedad, ya sea en forma asintomática (alrededor de dos semanas) o sintomática, donde mientras más grave el caso, más tiempo tarda la recuperación. Después de recuperarse uno puede seguir contagiando por aproximadamente una semana hasta finalmente ser inmune. El siguiente diagrama esquematiza aproximadamente este proceso con tiempos y porcentajes aproximados de las posibles etapas de la enfermedad a partir de todos los que se contagian. Estos tiempos y porcentajes son basados en estimaciones actuales, que seguro cambiarán al final de la pandemia, pero los usaremos sólo para ilustrar los problemas que existen en los datos (de hecho los asintomáticos ahora se estiman entre 30 y 43%).

El primer problema es la dimensión temporal del proceso. Por ejemplo, si detectamos hoy a dos personas enfermas, pero una lleva ya una semana enferma y la otra dos semanas, en los casos nuevos estamos realmente sumando peras con manzanas. Por esta razón, los modelos epidemiológicos usan ecuaciones diferenciales con respecto al tiempo, para integrar la información en forma coherente y poder hacer predicciones más precisas sobre el futuro.
En el caso particular de COVID-19, por tener una alta probabilidad de contagio (1 persona contagia en promedio más de 1 persona, digamos R personas, el factor de contagio), el crecimiento inicial es exponencial. Al final, cuando el contagio ya pasa a una gran parte de la población, comienza a crecer más lentamente pues es más difícil encontrar personas sanas. Si cada persona contagia exactamente a 2 personas al día, es decir R=2, tenemos que el total de los contagiados hoy, es igual a la suma de los casos nuevos de todos los días anteriores menos uno (sic). Esto significa que los números crecen tan rápido que los mismos tienen una incertidumbre mayor (mayor varianza en términos estadísticos). Por otro lado, como es esperable, la duración de la enfermedad es distinta para cada persona, pues depende del género (más casos en hombres), de la edad (más edad, más peligro), de la salud (menos salud, más peligro) y de otras características personales (fumador/a, etc.). Estos dos factores, el crecimiento exponencial y las diferencias individuales generan mucho ruido en los datos, lo que hace aún más difícil su análisis y agrega imprecisión a todos los resultados.
“Sólo tenemos una parte (pequeña) de los datos.”
El último problema son los sesgos de medición. Por ejemplo, unos días atrás se observó que el número de recuperados en Chile era exactamente los confirmados dos semanas antes (que incluso podrían incluir decesos). O si estamos contando todos los fallecidos, que parece ser un problema en España. O a que enfermedad atribuimos la muerte, a una condición de salud previa o al novel corona virus, una diferencia que se especula que ocurre en Alemania. O como decidimos cuando hospitalizar o pasar a la UCI a un enfermo. O cuando contabilizamos un caso nuevo hoy es debido al resultado de un test que se hizo varios días atrás, no hoy. Peor aún, en cada país hay políticas sanitarias distintas para contabilizar todos estos casos y entonces cuando comparamos países, por ejemplo usando el número de fallecidos, nuevamente estamos comparando peras con manzanas. Aún más imprecisión. Por lo tanto, que la tasa de letalidad [1] de casos de un país sea mejor que la de otro país, puede deberse sólo a una ilusión provocada en parte por los sesgos de medición. Notar que sólo hemos mencionado los sesgos de medición más importantes, pero seguro que hay otros.
A todo esto tenemos que agregar que sólo tenemos parte de los datos, pues no se realizan tests a todas las personas. Peor aún, la mayoría de los tests se hacen a personas que se sienten mal y por lo tanto hay un sesgo hacia los casos sintomáticos. Así que todos los datos sobre enfermos son cotas inferiores del valor real, las cuales dependiendo de la sintomatología son más o menos precisos. Consideremos los datos de Chile para el 1 de abril (columna Conocidos y los valores en negro) de la siguiente tabla.

El tener información parcial hace mucho más difícil entender la realidad. Por ejemplo, si calculamos la tasa de letalidad de casos (16/3.031) obtenemos 0,5%, lo que es muy poco respecto al resto del mundo, donde se obtienen valores mayores al 1%. Además no considera que los decesos ocurren al final de la enfermedad y entonces sólo habría que considerar los enfermos de hace tres semanas o más. De hecho la recomendación de los expertos es dividir el número de fallecidos por ellos mismos más los recuperados (16/250), lo que da un 6%, más alto que la mayoría de los países (pero ya vimos que los recuperados, que ya son inmunes, no están bien medidos). Todo lo anterior implica que los datos pueden ser incoherentes, otro problema que ya se ha detectado, lo que agrega aún más ruido.
Para entender cuanto desconocemos, podemos hace un análisis factual reverso. El resultado son los números rojos de la tabla anterior, donde los números negros es lo que suponemos sabemos o deberíamos saber a ciencia cierta. Para los interesados y/o los que gustan de las matemáticas, adjunto este análisis simple en un anexo. Este tipo de análisis, pero mucho más sofisticado, es el que usaron investigadores del Imperial College en el Reino Unido para mostrar que el número de contagiados en Europa era mucho mayor de lo que se pensaba, entre 17 y 188 veces más para el caso de España. El amplio rango de estos números se debe a las imprecisiones que se han mencionado. En nuestro ejemplo es sólo de 5 veces más.
“¿Podemos mejorar la calidad de los datos? Si, en parte.”
Todo lo anterior cambia dependiendo de los parámetros que usemos. Sin embargo siempre obtendremos que los datos que tenemos ahora son parciales y no dejan ver la situación real con exactitud, ya que usamos valores conservadores. Por lo tanto actualmente estamos conduciendo con un auto con bastante barro en los parabrisas. Si ese fuera ese el caso, siguiendo la metáfora, sería fácil limpiar el parabrisas. Pero, ¿podemos mejorar la calidad de los datos? Si, pero no del todo.
No podemos cambiar la imprecisión que se debe a la complejidad del problema pero si podemos eliminar muchos de los sesgos de medición. Este rol debe tomarlo la OMS que ya lo hace en cierta medida, pero se tiene que estandarizar más como se cuentan e informan los datos relativos a una pandemia. También es necesario desarrollar mejores políticas de medición. Para todo esto es necesario que haya más colaboración entre países, un dilema futuro destacado por Harari.
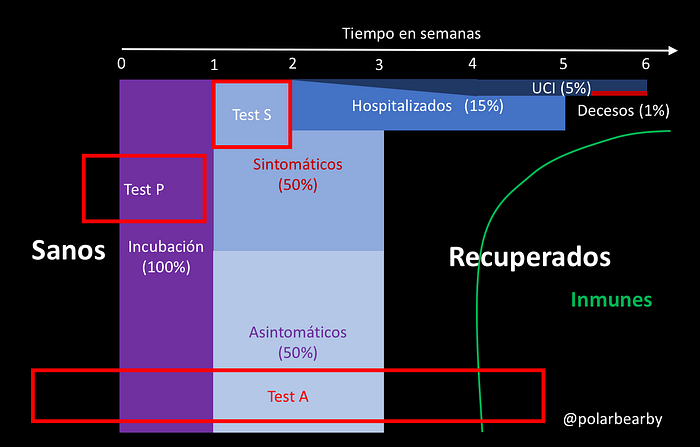
De estas políticas, la más importante desde el punto de vista de datos es la referente a los tests. Por ejemplo, saber exactamente cuántos tests correctos se hacen al día, a quién se hacen, cuantos son positivos y que siempre se informen con el mismo retraso conocido de tiempo (por ejemplo, dos días), sino estamos agregando ruido en los datos. Los tests actuales en su mayoría son reactivos y sesgados a personas que tienen la enfermedad (de hecho si los síntomas son claros, es un test que sería más útil en un potencial enfermo), los Test S en el diagrama de arriba. Sin embargo también necesitamos hacer tests masivos a personas que se sienten bien en lugares de mucho contacto físico (medios de transporte, lugares muy transitados) y en barrios completos donde creemos que hay pocos contagiados (Test A en el diagrama anterior para ambos casos). También hay que hacer tests a grupos de riesgo (personas en contacto con enfermos que se sienten bien pero que pueden ya haberse enfermado, Test P) y así sabremos cuál es la realidad en cada caso.
“Debemos hacer tests masivos a personas que se sienten bien”
Estos tests permitirían (1) entender mejor el alcance de la infección, (2) detectar enfermos asintomáticos que deberían estar en cuarentena pero están contagiando en lugares de alta densidad de personas y (3) personas que han pasado la enfermedad sin saberlo y que ya son inmunes, por lo cual podrían ser voluntarios para tareas de alto riesgo o que pueden volver ya a su trabajo y ayudar a reactivar la economía antes. En el futuro incluso podría tener sentido emitir un carnet de inmunidad para éste y otros virus de alta mortalidad. Estos tests además deberían complementarse con encuestas por Internet para validar de otra manera los datos que se están obteniendo.
Finalmente, la mayor cantidad posible de datos de pandemias, por supuesto anonimizados y localizados a nivel de comuna para proteger la privacidad, deberían ser abiertos. Esto permitiría entender la red de contactos físicos, permitir un confinamiento parcial y volver antes al trabajo. Pero no sirve de nada tener datos abiertos si no son de buena calidad, pues tener datos abiertos malos es muchas veces peor que no tenerlos. Así que nuestro objetivo no debe ser datos per se o datos masivos, sino datos correctos, y si es posible, completos.
Anexo: Análisis Factual Reverso
El propósito de este análisis es obtener una cota inferior (es decir, una estimación por abajo u optimista) del número de contagiados en Chile. Una versión sucinta de este análisis en inglés, para California y los Estados Unidos, también está disponible. Un estudio mucho más sofisticado que muestra la impresición de los números para toda Europa fue realizado en el Imperial College y muestra que las cotas inferiores que obtenemos son realistas (igual este modelo ha sido criticado).
El dato más preciso es el número de fallecidos y si usamos que la tasa de letalidad de la infección [1] es del 1%, tenemos que el número de casos debiera ser 1.600, muchos menos de los que tenemos. ¿Cómo se explica esto? Según nuestro diagrama, los decesos pueden ocurrir a partir del ingreso en la UCI, digamos a las 3 semanas. Sin embargo, si suponemos que el número de casos informados es una fracción constante de los reales, podemos inferir de los datos que eso es cierto para 10 días de antelación (básicamente porque las muertes divididas por los casos 10 días antes es aproximadamente constante). Por lo tanto debemos mirar cuantos casos habían el 22 de marzo: 632, bastante menos que 1.600. De hecho de estos 632, es posible que varios de ellos sean parte de los decesos, pero no tenemos los datos individuales para comprobarlo.
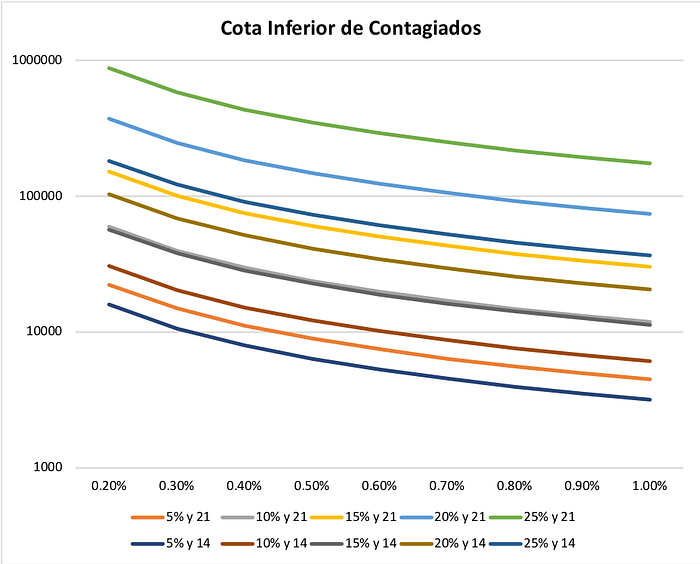
No sabemos el factor de contagio diario, R, pero lo podemos estimar (con error) a partir de los datos parciales (R no es lo mismo que R0, el ritmo básico de reproducción, que es el número total de personas que contagia una persona en el período total en el que sufre la infección). Es decir 3.031 = 23 R^21, con lo que obtenemos R =1,26 (otras estimaciones más precisas son similares) o en forma equivalente, un factor semanal de contagio de 5,1. En otras palabras, cada persona contagia en promedio a otras 1,26 personas al día o a 5,1 a la semana. Aplicando este factor de contagio a los 1.600 casos, tenemos que el 1 de abril deberían haber habido un poco más de 16 mil enfermos, de los cuales sólo conocemos 3.031, que supondremos son todos sintomáticos (los tests se hacen mayoritariamente a las personas que llegan enfermas). El siguiente gráfico muestra como esta cota inferior varía si cambiamos la tasa de letalidad, el porcentaje de aumento diario y el número de días promedio que pasan antes de que la persona fallezca (aquí usamos 14 y 21 días, así que el resultado es pesimista).
Es decir hay al menos 8.069 enfermos sintomáticos (50%), de los cuales sólo conocemos un poco más de 3 mil (3%), lo que significa que a finales de abril podríamos tener más de mil personas hospitalizadas y muchas de ellas en la UCI. Y también tenemos el mismo número de personas sin síntomas que lamentablemente pueden estar contagiando a otras personas sin saberlo. Ahora, de los 1.600 casos que teníamos hace tres semanas, la mitad son sintomáticos y según nuestro diagrama, se acaban de recuperar. Para los asintomáticos, necesitamos la mitad de los casos de hace dos semanas para contar a los recuperados, es decir 4.034 (800 R^7). Esto da un total de al menos 4.834 recuperados, pero sólo conocemos 234 (5%). Y los recuperados son los que ya deberían ser inmunes y ellos también crecen exponencialmente, pero con un retardo de dos o tres semanas, que es la duración de la enfermedad.
Otro dato bastante preciso es el número de personas en la UCI (173). Si consideramos que esas personas entraron en las últimas dos semanas y que el 20% de ellas muere, de acuerdo al diagrama anterior, tenemos que tener una tasa de contagio al día de 1,24 para que sea coherente con el análisis que hemos hecho, que es menos de 2% menor al que usamos, lo que permite en cierta medida validar nuestra cota inferior. Y si un tercio de las personas hospitalizadas va a la UCI, podemos estimar el total de hospitalizados en 519. Por otro lado, si el 15% de los enfermos va al hospital, tenemos una cota superior de 2420.
Notar que hay varias suposiciones subyacentes en el análisis anterior. Primero, que no hay saturación en el proceso de infección. Es decir la probabilidad de encontrar una persona infectada es muy baja y el proceso de contagio de cada persona es independiente (esto es cierto en la etapa inicial en la que estamos). Segundo, la tasa de letalidad de infección que usamos es alta, porque queremos subestimar el número de enfermos. El 1% es una cota superior basada en los dos casos en que se hicieron tests a todo un grupo (más de tres mil personas en cada caso). El primero es el crucero Diamond Princess en Japón, donde la tasa de letalidad fue al final de 1,5%, pero este número está sesgado a un pasaje bastante mayor. El segundo caso es el pueblo de Vò en Italia, donde el 1,1% murieron, pero hay un sesgo de selección pues se eligió ese pueblo porque fue donde murió una de las primeras personas en Italia. En base a datos de China, la tasa de letalidad se ha estimado en 0,7%. Si transformamos este resultado a la pirámide de edad de Chile, tendríamos un 0,6%. Tercero, tampoco analizamos exactamente la parte dinámica del problema pues las tasas de contagio no son constantes, pero usamos una cota inferior para ellas. Cuarto, usamos semanas para extrapolar en el futuro, la realidad es distinta para cada enfermo, pero siempre usamos valores conservadores para subestimar los resultados. Quinto, no se conoce el porcentaje exacto de casos asintomáticos. Aquí para simplificar el ejemplo y enfatizar el mayor peligro de contagio en estos casos, hemos usado 50% (como en Vò o similar al crucero donde fue 48%), pero las estimaciones varían entre 18% y 42%. Además en una población más joven como es el caso de Chile este porcentaje debería aumentar. Sexto, suponemos que no hay colapso del sistema sanitario, pues en ese caso podrían haber muertes por falta de recursos médicos y otras complicaciones que son las razones por las cuáles es importante limitar la rapidez del contagio. Séptimo, suponemos que no hay posibilidad de reinfección, al menos en el corto plazo, lo que podría no ser cierto de acuerdo a eventos recientes en Corea del Sur. Esto invalidaría todos los modelos propuestos.
[1] Usamos tasa de letalidad de la infección (IFR) para el número de decesos dividido por el número total de infectados al final de la pandemia (que no se conoce ni se conocerá nunca por todos los casos asintomáticos, siempre es estimada) y tasa de letalidad de casos (CFR) para el número de fallecidos dividido por los casos conocidos de personas enfermas cuando se enfermaron los fallecidos (o los fallecidos más los casos conocidos de recuperados), aunque la mayoría usa incorrectamente los fallecidos actuales, que en ambos casos sobrestima en general la tasa de letalidad de la infección, ya que ambos datos son parciales y el denominador está más subestimado que el numerador.
